Amazon Aurora DB 클러스터란
- Amazon Aurora DB cluster는 하나 이상의 DB 인스턴스와 이 DB 인스턴스의 데이터를 관리하는 클러스터 볼륨으로 구성됩니다.
- Aurora 클러스터 볼륨은 다중 가용 영역을 아우르는 가상 데이터베이스 스토리지 볼륨으로서, 각 가용 영역에는 DB 클러스터 데이터의 사본이 있습니다.
- Aurora DB 클러스터는 다음과 같이 두 가지 유형의 DB 인스턴스로 구성됩니다.
기본 DB 인스턴스 – 읽기 및 쓰기 작업을 지원하고, 클러스터 볼륨의 모든 데이터 수정을 실행합니다. - Aurora DB 클러스터마다 기본 DB 인스턴스가 하나씩 있습니다.
Aurora 복제본 – 기본 DB 인스턴스와 동일한 스토리지 볼륨에 연결되며 읽기 작업만 지원합니다. - 각 Aurora DB 클러스터는 기본 DB 인스턴스에 더해 최대 15개까지 Aurora 복제본을 구성할 수 있습니다. - Aurora 복제본을 별도의 가용 영역에 배치하여 고가용성을 유지합니다. - Aurora는 기본 DB 인스턴스를 사용할 수 없는 경우 자동으로 Aurora 복제본으로 장애 조치합니다. - Aurora 복제본에 대해 장애 조치 우선 순위를 지정할 수 있습니다. - 또한 Aurora 복제본은 기본 DB 인스턴스에서 읽기 워크로드를 오프로드할 수 있습니다.
다음은 클러스터 볼륨과 Aurora DB 클러스터에 속하는 기본 DB 인스턴스 및 Aurora 복제본 사이의 관계를 나타낸 다이어그램입니다.
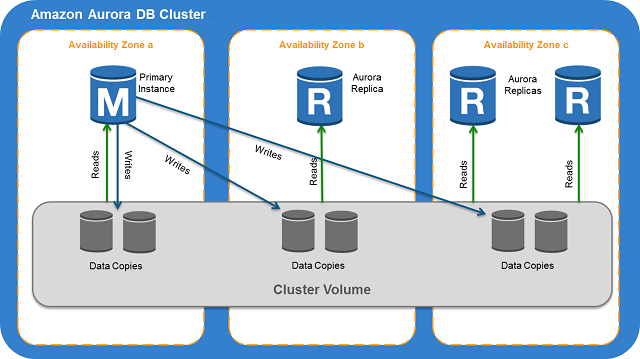
- Aurora 클러스터를 보면 컴퓨팅 용량과 스토리지가 분리되어 있습니다. 예를 들어 DB 인스턴스가 1개뿐인 Aurora 구성또한 클러스터입니다. 기본 스토리지 볼륨에는 여러 가용 영역(AZ)으로 분산된 다수의 스토리지 노드가 포함되어 있기 때문입니다.
- Aurora DB 클러스터의 입출력(I/O) 작업은 라이터 DB 인스턴스인지 리더 DB 인스턴스인지에 관계없이 동일한 방식으로 계산됩니다. 자세한 내용은 Amazon Aurora DB 클러스터의 스토리지 구성 섹션을 참조하세요.